안녕하세요
오늘은 머신러닝 주요 문제 유형에 대해 알아보겠습니다.
본격적인 머신러닝 활용 사례를 알아보기 전에 대표적으로 어떤 문제를 해결하기 위해 어떤 모델이 사용되는지 알아보겠습니다. 문제 유형을 잘 구분하여 사용해야 모델의 학습 성능을 높일 수 있습니다.
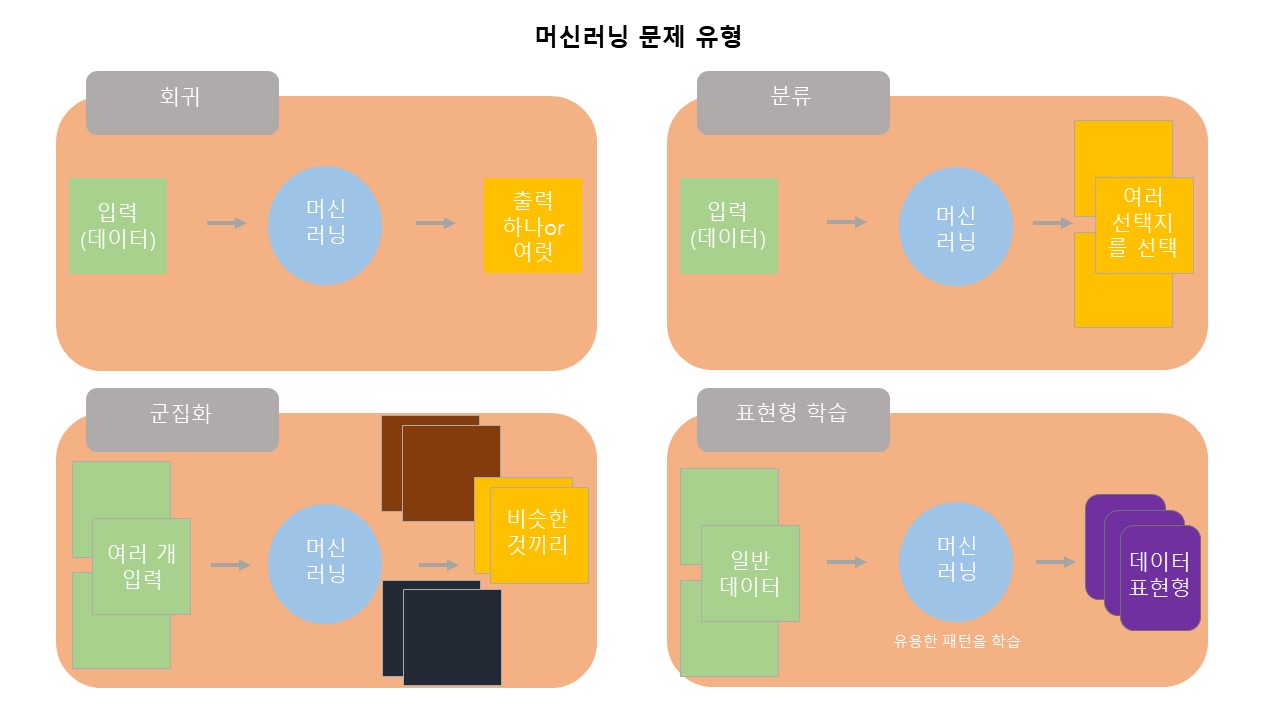
문제 유형에는 '회귀', '분류', '군집화', '표현형 학습'이 있습니다.
'회귀' 문제'는 머신러닝 중 가장 기본이 되는 문제 유형으로, 입력된 데이터에 대해 적합한 숫자값을 예측하는 문제입니다. 데이터들의 값을 입력 분석하여 의미 있는 값으로 출력하는 가장 기본적인 알고리즘 형태가 되겠습니다. 기본적인 이유는 출력되는 값의 해석이 여러가지로 풀이되어 여러 문제를 포함하기 때문입니다. 그리고 이런 회귀 문제를 해결하기 위한 머신러닝 기법 또한 다른 머신러닝 기법의 기초가 되는 경우가 많습니다. 대표적으로 회귀 문제를 계산하는 기법에는 '선형 회귀', '가우시안 프로세스 회귀', '칼만 필터'가 있습니다.
'분류' 문제는 회귀 문제 만큼이나 기본적인 머신러닝 문제입니다. 분류 문제는 머신러닝의 기본 문제인 회귀 기법으로도 분석이 가능하지만 손실함수를 최적화하여 해결하는 방법을 많이 사용하고 있습니다. 분류 문제란 주어진 입력 값에 대해 여러가지 중 한가지 혹은 여러개의 값을 선택하는 것입니다. 이 때 한 가지를 선택하면 '멀티클래스'분류, 여러 개를 선택하면 '멀티 레이블'이라고 합니다. 즉 분류란 주어진 상황(데이터)를 보고 관련 있는 모든 것(가능성)을 보여주는 것이기 때문에 보편적으로 활용하고 있습니다. 대표적 문제 기법에는 '로지스틱 회귀', '서포트 벡터 머신', '신경망' 등이 있습니다. 추가로 입력 값이 시간에 따라 변화하는 데이터이고 그것을 모델링 하는 기법에는 'CRF'와 'RNN' 등이 있습니다.
'군집화'는 비슷한 성격의 데이터를 서로 묶는 머신러닝의 문제입니다. 입력 값이 정해져 있는것이 아니라 데이터 성격별로 분류를 통해 구분하는 것입니다. 현재의 데이터를 분석할 때 사용하며 기존 데이터와 분석하여 미래 데이터를 군집화할 수 있습니다. 대표적으로 문서에 활용 될 때 '토픽 모델링'을 사용합니다. 군집화 문제에서 가장 중요한 것은 비슷한 것끼리 구분할 수 있는 데이터의 '유사도' 입니다. 유사도를 어떻게 정의하느냐에 따라 결과가 크게 달라집니다. 대표적인 군집화 문제 기법에는 'K-평균 군집화'와 '평균이동 군집화'가 있습니다.
'표현형 학습(임베딩학습)'은 풀고자 하는 문제에 적합한 표현형을 데이터로부터 추출하는 것입니다. 데이터 자체의 문제보다 근본적인 문제입니다. 쉽게 배울 수 있는 데이터를 통해 학습하여 다른 데이터를 해결합니다. 대표적으로 'word2vec모델','행렬 분해' 등이 있습니다.
기본적인 문제부터 여러가지 조건이나 학습을 통해 변형되는 문제까지 다양한 형태의 데이터 문제를 통해 머신러닝은 지속적으로 발전해오고 있습니다. 앞으로 더 다양하고 복잡한 문제가 나타났을 때 효과적으로 해결하기 위해서는 기본 문제서부터 차근차근히 개념을 명확히 이해하는 것이 중요하겠습니다. 다음에는 다양한 사례에서 사용되는 기법에 대해 설명드리도록 하겠습니다.
감사합니다.
'머신러닝' 카테고리의 다른 글
| [머신러닝 입문]구매 이력 데이터를 이용한 사용자 그룹 만들기 (0) | 2020.04.04 |
|---|---|
| [머신러닝 입문]문서 분석 시스템 만들기 (0) | 2020.04.03 |
| [머신러닝 입문]머신러닝 주요 모델-데이터양과 품질/표준화 (0) | 2020.03.31 |
| [머신러닝 입문]머신러닝 주요 모델 - 데이터형 (0) | 2020.03.31 |
| [머신러닝 입문]머신러닝 주요 개념-모델 평가 (0) | 2020.03.29 |